
Big data puede ser utilizado por el operador para los siguientes escenarios:
- Comprender la estructura del tráfico por protocolos y aplicaciones y su dinámica para formar planes de tarifas atractivos, identificar puntos de peering y optimizar las rutas.
- Supervisar la calidad de los enlaces de aplicaciones para aplicaciones específicas y reaccionar rápidamente ante problemas con el tráfico de la red WAN.
- Identifique los abonados problemáticos en función de la latencia y las solicitudes de paquetes para solucionar problemas y mejorar la fidelidad de los abonados.
- Supervise de forma proactiva las ciberamenazas basándose en las estadísticas de llamadas de los abonados mediante la base de datos de alimentación de Kaspersky para reducir el número de BotNet en la red.
- Supervise los ataques DDoS y reaccione a tiempo ante los picos de tráfico.
3 minutos para construir un informe sobre 1 petabyte de datos
Consideremos el ejemplo de un operador con 1 millón de abonados. Según nuestra experiencia, se supone que un operador de este tamaño tiene unos 2 Tbps de tráfico pico.
Para trabajar con casos de negocio típicos operadores:
- Almacenar las estadísticas IPFIX «en bruto» durante 24 horas, lo que supone aproximadamente 45 TB.
- Luego, utilizando los algoritmos de QoE de Stor, los datos se agregan para su almacenamiento y se reducen en un factor de 5. Los datos agregados se almacenan normalmente durante 3 meses, lo que supone unos 900 TB .
Combinado con otros tipos de datos (por ejemplo, registro NAT o registro GTP), nuestro operador de referencia sale a unos 1 petabyte .
Sin embargo, no sólo es importante obtener los datos, sino también asegurarse de que estén disponibles y se procesen rápidamente. Los ingenieros del operador y los especialistas en marketing trabajan con ellos a diario: elaboran informes sobre diversos campos y filtros para toda la profundidad de almacenamiento de datos. Para que el trabajo de los usuarios sea cómodo, el tiempo de creación de informes por filtros no debe superar los 3 minutos .
Los datos de la base de datos también se utilizan regularmente para enviar informes periódicos a los servicios del operador por correo electrónico/telegrama y para elaborar cuadros de mando.
Puede calcular el volumen de las estadísticas de su operador utilizando la calculadora.
Componentes de la solución
La adquisición de datos se realiza en varias etapas:
- Paso del tráfico a través del SSG para analizarlo por firmas (protocolos y aplicaciones).
- Envío de estadísticas desde el SSG mediante el protocolo IPFIX (NetFlow v10), que se realiza a través del equilibrador ipfixcol2 para distribuir uniformemente las estadísticas entre los nodos y proporcionar tolerancia a fallos en caso de que falle un nodo.
- Recepción de estadísticas en QoE Stor mediante ipfixreceiver2.
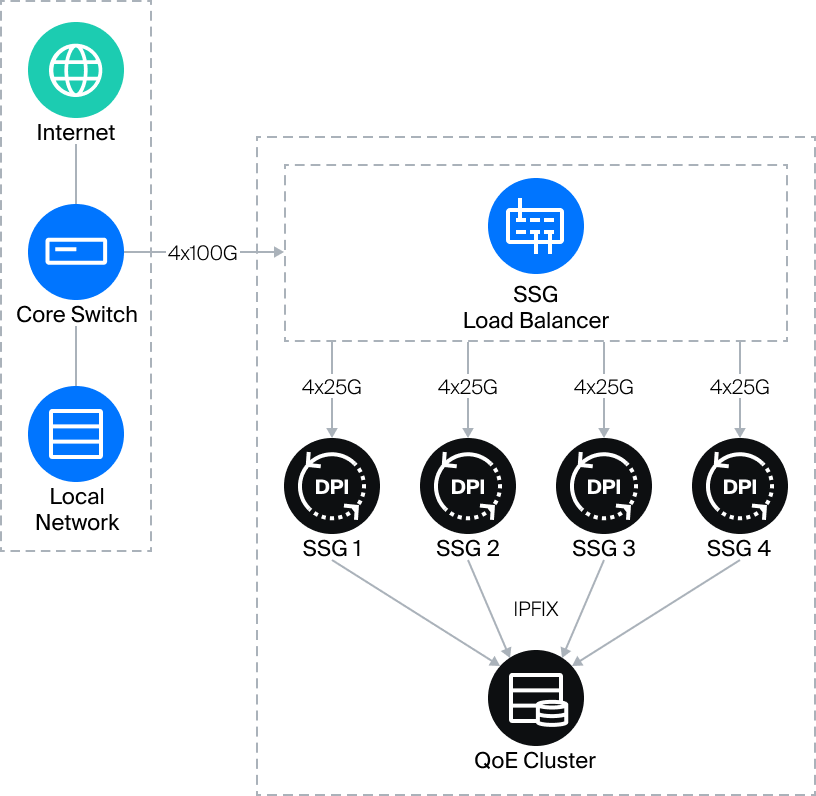
En caso de que el volumen de tráfico sea superior al que puede gestionar un único SSG, se utiliza un clúster DPI. El tráfico se extrae de la parte central de la red y se envía al SSG Load Balancer, que distribuye la carga uniformemente entre varios servidores SSG. El equilibrador de carga es capaz de gestionar hasta 800 Gbps de tráfico duplicado.
Puede encontrar información más detallada sobre el funcionamiento del equilibrador de carga en nuestra base de conocimientos.
Clúster QoE
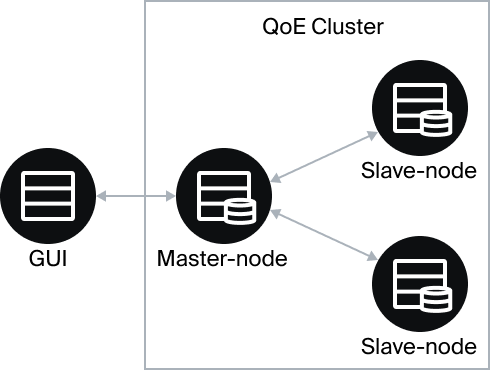
QoE Stor básicamente utiliza una base de datos ClickHouse con la capacidad de crear un clúster de múltiples nodos:
- Se asigna un nodo maestro al clúster, que recibe una solicitud de la GUI y envía solicitudes al nodo esclavo.
- Cada nodo esclavo crea un informe basado en sus propios datos y lo envía al nodo maestro.
- El nodo maestro agrega las respuestas recibidas del nodo esclavo y realiza la representación resultante para su visualización en la GUI.
Esta jerarquía permite realizar un escalado lineal del clúster cuando se añaden nuevos nodos sin tener que aumentar el rendimiento del nodo maestro. GUI trabaja con el clúster en un modo especial (habilitado por una opción separada en la configuración), modificando las consultas SQL para que los nodos construyan informes listos para el encolado. Sin este modo, el clúster es sólo un almacenamiento distribuido, y el rendimiento sólo está limitado por el rendimiento del nodo maestro y el ancho de banda de la red entre los nodos QoE.
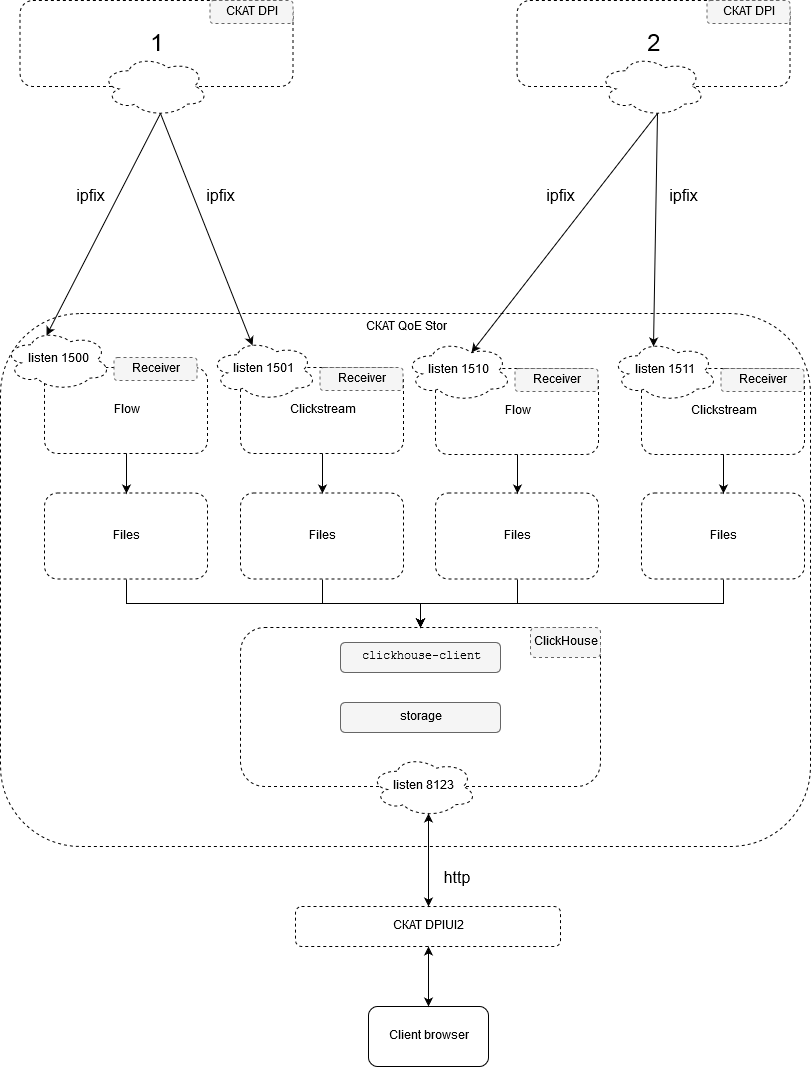
QoE Stor realiza el procesamiento de datos en varias etapas:
- ipfixreceiver2 recibe y escribe datos sin procesar en un archivo de texto con una frecuencia especificada (10 seg.-10 min.) en el default-disk.
- El postproceso realiza la agregación de los datos sin procesar para reducir el espacio de almacenamiento y rellenar las tablas para crear informes. El paso de agregación dura de 1 minuto a 1 hora.
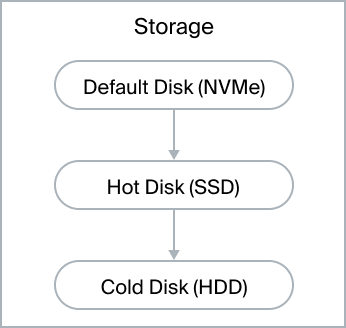
Se utilizan varios tipos de discos para optimizar el coste de almacenamiento:
- default – discos rápidos para recibir datos y realizar el proceso de agregación, se recomiendan los SSD NVMe.
- Los SSD NVMe son los discos más rápidos para recibir datos y realizar el proceso de agregación.
- caliente – discos para almacenamiento durante el periodo en el que habrá una alta probabilidad de solicitar informes sobre estos datos, normalmente hasta 3 meses.
- fríos – discos lentos de gran volumen para el almacenamiento a largo plazo, se recomienda utilizar HDD.
- Discos de gran capacidad.
Período de almacenamiento en cada nivel se establece en la configuración a través de GUI. El movimiento de datos entre discos y la limpieza de datos se realiza automáticamente de acuerdo con la configuración. También hay un mecanismo de control de desbordamiento para proteger la base de datos.
Para obtener más información sobre las ventajas de Stingray Service Gateway y el módulo de análisis QoE, póngase en contacto con VAS Experts. Deje una solicitud de prueba para evaluar objetivamente las capacidades y la funcionalidad del software.
Suscríbete al boletín del blog para no perderte nuevos materiales.[/suscripción].