
Bien qu’il n’y ait aucun problème avec les réseaux locaux (LAN) en raison de leur bande passante élevée, la bande passante limitée des canaux d’accès à Internet (WAN) nécessite un réglage précis.
Classification et marquage
La fourniture de services d’accès à Internet est orientée vers l’utilisateur, et le plus important est la perception qu’a l’utilisateur de la qualité du service : Internet ne doit pas « ralentir », les applications doivent répondre rapidement aux commandes, les fichiers doivent se télécharger rapidement et les appels vocaux ne doivent pas être saccadés, sinon l’utilisateur commencera à chercher un autre fournisseur de services. La gestion du trafic des canaux d’accès à Internet, les paramètres de restriction et les priorités doivent répondre aux exigences des utilisateurs. Les informations sur les protocoles et les applications permettent également à l’administrateur de mettre en œuvre des politiques de sécurité pour protéger les utilisateurs du réseau.
La classification du trafic est la première étape pour identifier les différentes applications et protocoles transmis sur le réseau. La deuxième étape consiste à gérer, optimiser et hiérarchiser ce trafic. Après la classification, tous les paquets sont marqués en fonction de leur appartenance à un protocole ou à une application spécifique, ce qui permet aux périphériques réseau d’appliquer des politiques de service (QoS) basées sur ces étiquettes et ces indicateurs.
Concepts clés : classification – identification des applications ou des protocoles ; marquage – processus de balisage des paquets pour l’application de politiques de service sur les équipements.

Il existe deux méthodes principales de classification du trafic :
- Classification basée sur la charge utile. Elle repose sur des champs de blocs de données tels que les ports OSI de couche 4 (expéditeur et destinataire ou les deux). Cette méthode est la plus courante, mais elle ne fonctionne pas avec le trafic crypté et tunnelisé.
- Classification basée sur des statistiques. Elle repose sur l’analyse du comportement du trafic (temps entre les paquets, durée de la session, etc.).
Une approche universelle de la classification du trafic repose sur les informations contenues dans l’en-tête du paquet IP, généralement l’adresse IP (couche 3), l’adresse MAC (couche 2) et le protocole utilisé. Cette approche a des capacités limitées, car les informations sont uniquement tirées de l’en-tête IP, tout comme les méthodes de couche 4 sont limitées. Après tout, toutes les applications n’utilisent pas des ports standard.
Une classification plus sophistiquée peut être obtenue grâce à l’inspection approfondie des paquets (DPI). Cette méthode est la plus précise et la plus fiable, examinons-la donc de plus près.
Deep Packet Inspection
Les systèmes d’inspection approfondie des paquets vous permettent de classer les applications et les protocoles qui ne peuvent être identifiés aux couches 3 et 4, tels que les URL dans les paquets, le contenu des messages instantanés, le trafic vocal Skype et les paquets p2p BitTorrent.
Le principal mécanisme d’identification des applications dans le DPI est l’analyse des signatures . Chaque application possède ses propres caractéristiques uniques, qui sont enregistrées dans une base de données de signatures. La comparaison d’un échantillon provenant de la base de données avec le trafic analysé permet d’identifier avec précision l’application ou le protocole. Cependant, comme de nouvelles applications apparaissent régulièrement, la base de données de signatures doit également être mise à jour pour garantir une grande précision d’identification.
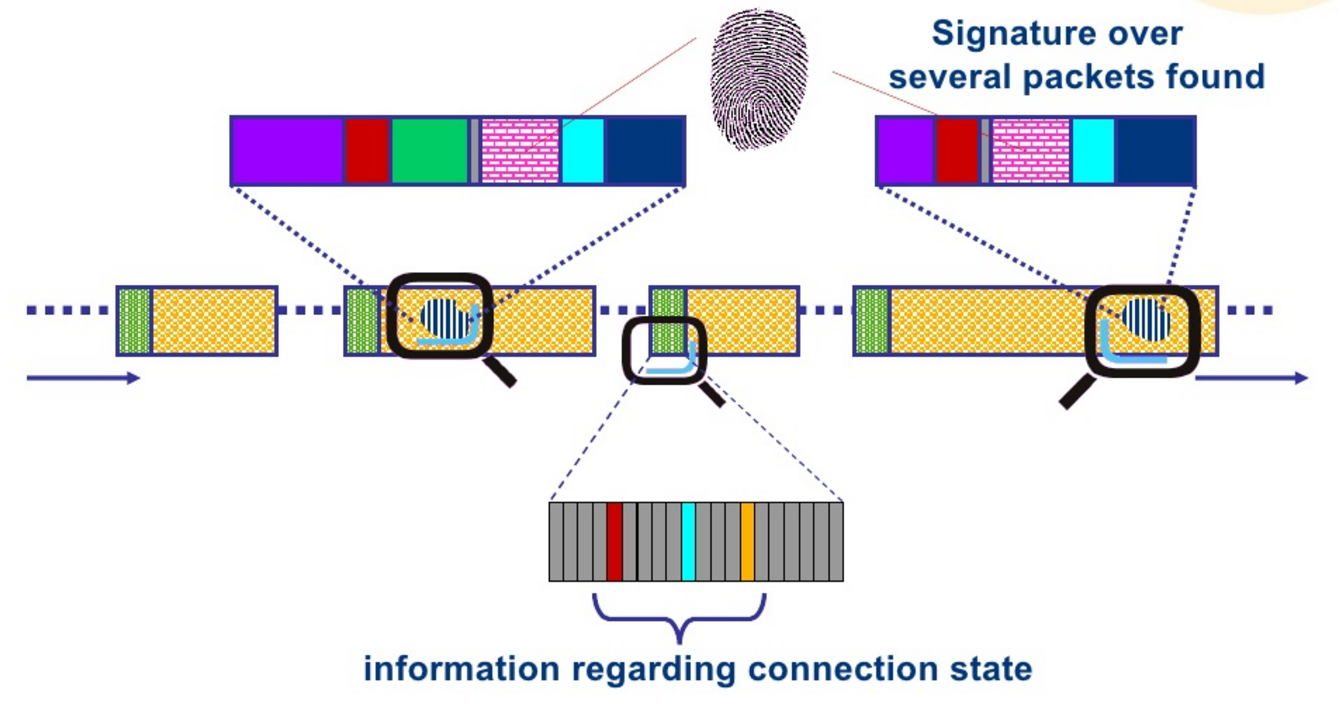
Il existe plusieurs méthodes d’analyse des signatures :
- Analyse des modèles (Pattern analysis)
- Analyse numérique (Numerical analysis)
- Analyse comportementale (Behavioral analysis)
- Analyse heuristique (Heuristic analysis)
- Analyse des protocoles/états (Protocol/state analysis).
Analyse des modèles
Certaines applications contiennent des échantillons spécifiques (octets/caractères/chaînes) dans le bloc de données du paquet qui peuvent être utilisés à des fins d’identification et de classification. Ces échantillons peuvent se trouver n’importe où dans le bloc de données ; cela n’affecte pas le processus d’identification. Cependant, comme tous les paquets ne contiennent pas d’échantillon d’application, cette méthode ne fonctionne pas toujours.
Analyse numérique
L’analyse numérique étudie les caractéristiques quantitatives des paquets, telles que la taille du bloc de données, le temps de réponse des paquets et l’intervalle entre les paquets. Par exemple, l’ancienne version de Skype (antérieure à la version 2.0) se prêtait bien à ce type d’analyse, car la requête du client était de 18 octets et la réponse reçue était de 11 octets. Comme l’analyse peut être répartie sur les paquets d’une chaîne de magasins, la décision de classification peut prendre plus de temps. L’analyse simultanée de plusieurs paquets prend beaucoup de temps, ce qui rend cette méthode peu pratique.
Analyse comportementale et heuristique
Cette méthode est basée sur le comportement du trafic généré par une application en cours d’exécution. Pendant son exécution, l’application génère un trafic dynamique qui peut également être identifié et marqué. Par exemple, BitTorrent génère un trafic avec une séquence spécifique de paquets ayant les mêmes caractéristiques (port entrant et sortant, taille des paquets, nombre de sessions ouvertes par unité de temps), qui peuvent être classés selon un modèle comportemental (heuristique).
Analyse du protocole/statut
Les protocoles de certaines applications sont une séquence d’actions spécifiques. L’analyse de ces séquences permet d’identifier l’application avec une précision suffisante. Par exemple, une requête GET provenant d’un client FTP doit être suivie d’une réponse correspondante du serveur.
De plus en plus d’applications sur Internet commencent à utiliser des mécanismes de chiffrement du trafic, ce qui pose des problèmes majeurs pour toute méthode de classification. Le système DPI ne peut pas examiner le contenu d’un paquet chiffré pour l’analyser. Les principales méthodes d’identification de ce type de trafic sont donc l’analyse comportementale et l’analyse heuristique, mais même celles-ci ne permettent pas d’identifier toutes les applications. Le dernier mécanisme en date, qui utilise simultanément ces deux méthodes, est appelé « clustering » et seul lui permet d’identifier le trafic chiffré.
La classification du trafic avec l’application ultérieure de politiques de qualité de service est l’une des tâches les plus importantes pour tout opérateur de télécommunications. L’utilisation de systèmes DPI modernes permet d’accomplir cette tâche avec une efficacité et une productivité maximales.
Abonnez-vous aux mises à jour de notre blog pour rester informé des dernières actualités.